Hadoop(一)Hadoop&HDFS简单介绍 |
您所在的位置:网站首页 › hadoop site › Hadoop(一)Hadoop&HDFS简单介绍 |
Hadoop(一)Hadoop&HDFS简单介绍
| 你是否像我一样对Hadoop这个东西感觉比较迷..? 你是否像我一样上课不听课甚至翘课于是现在感觉自己有点凉..? 那么..希望本篇文章及接下来的系列文章会对你有帮助(:D 首先照例官网是最好的教程! Hadoop系列文章001篇 Hadoop概述Hadoop到底是个啥?官方介绍:Hadoop是一个由Apache基金会所开发的,可靠的、可扩展的、用于分布式计算的分布式系统基础架构和开发开源软件。简单的说Hadoop软件库就是一个框架,通过这个框架你可以在计算机集群中对大规模的数据集进行分布式处理,可以理解成和操作系统的多线程并行有点像的一个东西。但是这个东西非常稳定,如果一个节点上的数据宕掉了还有神奇的机制可以保证数据备份在其他节点上,可以继续运行。 Hadoop架构核心包括: 分布式文件系统 HDFS(Hadoop Distributed File System) 分布式计算系统 MapReduce 分布式资源管理系统 YARN等下我们分别介绍一下这三个东西,先对他们有个大概的了解就好了 Hadoop特点 高可靠性:数据存储有多个备份,集群设置在不同的机器上,可以防止一个节点宕机造成集群损坏。当数据处理请求失败后,Hadoop会自动重新部署计算任务,对出现问题的部分进行修复或通过快照方式还原到之前的时间点。 高扩展性:Hadoop在可用的计算机集群见分配数据并完成计算任务的,在集群中添加新的节点是很容易的,所以集群可以容易的进行节点的拓展完成集群的扩大。 高效性:Hadoop可以在节点间动态的移动数据,数据可在节点间进行并发处理,并保证节点的动态平衡,因此处理速度非常快。 高容错性:和前面的高可靠性差不多,文件系统HDFS存储文件时如果某台机器宕机了或者读取文档出错,系统调用其他节点上的备份文件保证程序顺利运行。如果启动的任务失败,Hadoop会重新运行该任务或启用其他任务完成这个任务未完成的部分。 低成本 Hadoop基本框架用Java编写(我不想写JavaQAQ) HDFS概述HDFS又是个啥?HDFS是以分布式进行存储的文件系统,主要负责集群数据的存储和读取。是一个Master/Slave体系结构的分布式文件系统,HDFS实际上是运行在已有文件系统之上的一个文件系统,某种程度上你就理解成和你计算机的传统的文件系统差不多的一个东西就好了。同样的基本上面的Hadoop有什么特点HDFS就有这些特点。 HDFS特点HDFS被设计的时候主要是为了以下几个方面考虑的:1. 存储超大文件:适合存储大量文件(PB,EB以上都是没问题的);适合存储大文件(单个文件大小一般都是 百MB以上了);文件数目适中。 2. 流式文件访问:文件**一次写入,多次读取的访问模式**;支持追加操作,但无法更改已写入数据。 3. 普通商用硬件即可:不要昂贵的硬件,相对廉价的商用硬件就可以实现HDFS存储;当系统中某台/某几台服务器故障的时候,系统仍可用并且能保持数据完整。 基于以上的设计理念,我们自然的就可以想到 有这么几个场景是不适合使用HDFS的!:1. 低时间延迟的数据访问:HDFS 是为了高数据量的应用设计优化的,因此就以高时间延迟作为代价,如果服务的数据访问需要低时间延迟的话,那么HBase是个不错的选择。 2. 大量的小文件:由于Namenode将文件系统的元数据存储在内存中,因此HDFS能存的文件总数受限与Namenode的内存容量;根据经验,一般每个文件、目录、数据块的存储信息大约占150字节,存100万个文件大约需要300M内存。 3. 多用户写入,任意修改文件:HDFS只支持单个写入者;并且只能在文件末尾追加数据,不能修改已有内容。 歪一个楼我们可以顺便来回忆一下文件系统: (以下内容来自屁屁踢) 传统文件系统们 (依旧是知乎的markdown倒入不支持这个表格..大家自动脑补一下..?) 操作系统 | 文件系统 --- | ---: Windows | FAT32,NTFS,exFAT Linux/Android | ext3,ext4,xfs macOS/iOS | HFS+,APFS UNIX | JFS,JFS2,CDRFS,UDFS 分布式文件系统(Distributed File System): 文件系统管理的物理存储资源不一定直接挂载在本地节点上,而是通过计算机网络与节点相连。 常见类型: NFS (Network FileSystem): 比如说我们在做网安实验互相通过共享的网络文件夹里拷文件拷数字签名的时候可以把那个东西看成NFS,那种文件的组织形式和NFS我觉着有点像 GFS (Google Filesystem) HDFS (Hadoop Distribute FileSystem): 就是我们这里的HDFS话题再扯回来...!!! HDFS包括啥呢?主要包括一个NameNode, 一个Secondary NameNode, 多个DataNode 在了解概念之前我们先大概感受一下HDFS的架构!   然后让我们来了解一下这几个概念: Cluster 集群一个Hadoop Cluster由好多个Rack组成 Rack 机架一个Rack由好多个Node组成,比如说这样:  Client 客户端 Client 客户端需要访问HDFS文件服务的用户或应用所在的节点,包括: 命令行客户端(Shell命令)(这里就是你在macOS下的terminal到Hadoop的文件夹里然后操作的那些个命令) API客户端(Java程序)(我不想写Java!) MetaData 元数据元数据不是具体的文件内容,有三类重要信息: 文件和目录自身的属性信息。如文件名、目录名、文件和目录的从属关系、父目录信息、文件大小、目录大小、创建时间、修改时间、最后访问时间、权限等。 记录文件内容存储的相关信息。如文件分块情况、块ID、副本个数、每个副本(块)所在的DataNode信息等 记录HDFS中所有的DataNode信息,用于DataNode管理本文的最后一部分有关于元数据的更详细的载入和更新操作 Block 数据块 OSBLock是磁盘进行数据读写的最小单位,一般是512byte的整数倍,在HDFS中文件也有这种类似的分成块存储的一种机制文件在上传到HDFS时,HDFS将文件划分为多个分块(chunk),存储一个文件或一个文件的一部分。Hadoop2.x默认块大小为128MB(当然也有的版本为64MB这么大的分块)。 如要存储一个129MB的文件,则会被分成两个块来存储。Block被存储到各个节点,每个数据块都会备份副本。 文件本分成数据块按照抽象的数据块存储之后有啥好处呢..? 文件的大小可以大于网络中任意一个磁盘的容量 简化存储子系统(与元数据分离) 提高容错能力 NameNode 名称节点NameNode可以看成是集群的管理者,管理整个文件系统的命名空间,用于存储元数据及处理客户端发送的请求。 首先我们来看官方对NameNode相关功能的一些解释: NameNode中存放元信息的文件是fsimage文件。系统运行期间,所有对元数据的操作都保存在内存中,并被持久化到另一个文件edits中。当NameNode启动的时候,fsimage会被加载到内存中,然后对内存中的数据执行edits所记录的操作,以确保内存中保留的数据处于最新的状态。 再具体通俗的点解释一下,NameNode如何完成对整个文件系统的管理的呢? 我们都知道元数据存放了文件内容、名称、父目录等等的相关信息,同时还有DataNode的相关信息,那NameNode存放了元数据就意味着NameNode可以维护整个文件系统树及整棵树内所有的文件和目录。这些信息以镜像文件和编辑日志文件的形式永久的保存在本地磁盘上,在系统启动时被动态加载到内存中。同时包含了DataNode的相关信息,这些信息就是每个文件中各个块所在的数据的节点信息,这些信息会在系统启动时由数据节点重建。 NameNode这么重要!所以如果NameNode损坏将导致整个HDFS数据的无法访问。 这里涉及到两个名词:fsimage, edits那么这两个东西是啥呢? fsimage: 镜像文件,保存文件系统目录树信息,保存文件和块的对应关系 edits: 编辑日志文件,保存文件系统的更改记录。当客户端对文件进行写操作(包括新建和移动)时,操作首先记入edits,成功后才会更改内存中数据。edits并不会立刻更改硬盘上的fsimage 这两个名词以及NameNode的相关信息在本文的最后会有更详细的内容介绍 Secondary NameNode 辅助名称节点Secondary NameNode 听名字就知道是对NameNode的一个备份,备份了NameNode的数据,周期性的将edits文件合并到fsimage文件并在本地备份,以此来控制edits文件的大小在合理范围内,能缩短集群重启时NameNode重建fsimage的时间。同时能将新的fsimage文件存储到NameNode,取代原来的fsimage,删除edits文件,创建一个新的edits以便继续存储文件修改状态。 在NameNode元数据损坏的情况下,Secondary NameNode也可用作数据恢复,但不一定能恢复出全部数据。 但是要注意Secondary NameNode不是备份节点!! 同样的这个位置的关于HDFS的概念的几个名词在文章的最后会有更进一步的介绍。 DataNode 数据节点DataNode是真正存储数据的地方。在DataNode中文件以数据块的形式进行存储。当文件传到HDFS的时候。会被按照数据块的大小进行切割,每个块会被存储到不同的或者相同的DataNode并且备份副本,一般会默认存成3份,这样一个DataNode挂掉了之后,还会有其他两个上来顶替!比较稳妥!而被存成3份的数据块的DataNode会被NameNode记录下来,同时整个文件的分块信息也会被NameNode记录下来,确保在读取该文件时可以找到并整合所有的块。 每个块在存储到DataNode的同时,也会在本地文件系统中产生两个文件,一个是实际的数据文件,另一个是块的附加信息文件,其中包括数据的校验和,生成时间等。 DataNode通过心跳包和NameNode进行通讯。客户端读取/写入数据时在直接与DataNode通讯。 了解了HDFS的相关名词之后..那么问题来了..HDFS到底为什么这么神奇啊?HDFS有啥原理呢! HDFS分布式原理我们可以先大概感受一下HDFS的分布式存储 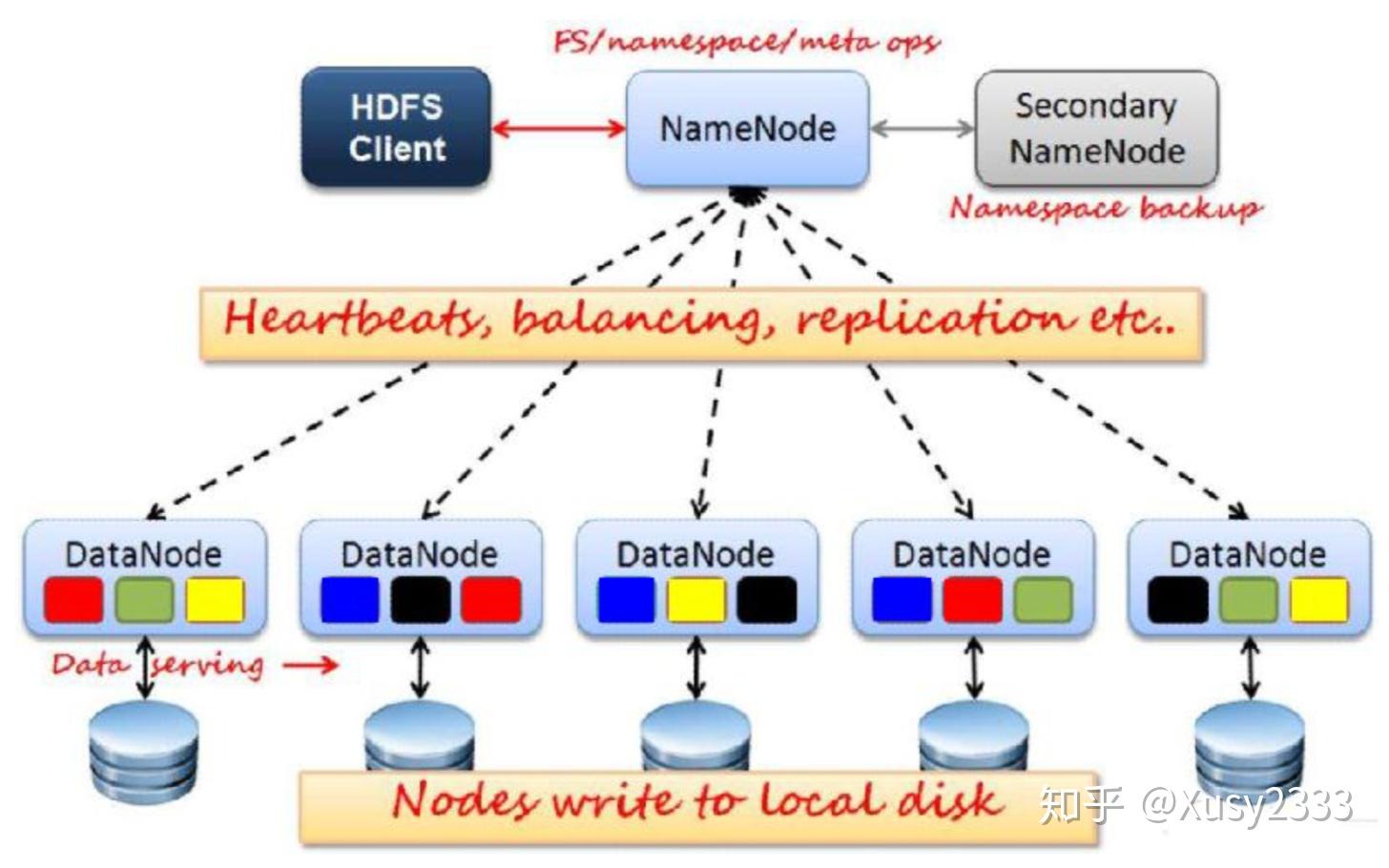  了解HDFS分布式原理之前我们有必要先了解一下分布式系统这个东西(当然我觉得大部分有常识的朋友应该是知道这个东西的所以你可以略过这段直接看正文) 分布式系统就是一个被划分成多个子系统或模块,各自运行在不同的机器上,几个子系统或模块间通过网络通信进行协作,实现最终整体功能的这么一个系统。一句话讲就是利用多个节点的共同协作完成一项或多项具体业务功能的系统。 了解HDFS分布式原理之前我们有必要先了解一下分布式系统这个东西(当然我觉得大部分有常识的朋友应该是知道这个东西的所以你可以略过这段直接看正文) 分布式系统就是一个被划分成多个子系统或模块,各自运行在不同的机器上,几个子系统或模块间通过网络通信进行协作,实现最终整体功能的这么一个系统。一句话讲就是利用多个节点的共同协作完成一项或多项具体业务功能的系统。 了解完分布式系统后..分布式文件系统就是分布式系统的一个子集,正像文章最开始提到的,分布式文件系统(这里指HDFS)主要解决的问题就是数据存储。再来一句话简单的说,它是横跨多台计算机的存储系统,存储在分布式文件系统上的数据能被自动划分到不同的节点上。 文件分布在多个集群节点上,节点间通过网络通信进行协作,提供多个节点的文件信息,让每个用户都能看到文件系统的文件,让多机器上多用户能共享文件和存储空间。 同时文件存储分块,数据块分布在各个节点并且在其他节点存储副本,这点在上面有提到。 数据读取时也会从多个节点读取。读取一个文件,从多个节点中找到存储该文件的数据块,分布读取所有数据块,然后按照文件对应数据块相关信息拼凑到一起去就读完了整个文件。 HDFS副本机制上面提到了每个数据块在其他节点中存储了副本,那么让我们具体的了解一下HDFS的副本机制。 每个数据库诶在HDFS中会存储多份,默认3份。副本在存放时按照以下策略进行: 使数据的可靠性和可用性最大化 使写入数据产生的开销最小化具体放置副本时努力达到两者之间的平衡进行放置。 存储副本的具体过程如下: 三副本存放策略(Block Placement Policy Default) 写请求方所在的机器如果是其中一个DataNode,则第一份副本直接存在写请求方的本地(写请求方就是要把数据写入我们的系统的那个请求方),否则随机选取集群中的一个DataNode。 第二个副本存放在不同宇第一个副本所在的机架中。 第三个副本存放在第二个副本所在的机架,但不属于同一个节点。 其余副本存放策略如果这个系统副本备份机制默认3份以上的话,其余副本存放遵守以下原则: 一个节点最多放置一个副本 如果副本数少于2倍机架数,同一机架不能放置超过2个副本 HDFS写流程 上面提到了写请求方,那我么就来讲讲写流程。 HDFS Client缓存在本地的要存入文件系统的数据达到了一个数据块大小时,Client创建一个Distributed File System对象,这个对象通过RPC协议(一个网络通信协议)向NameNode申请注册成为一个新的块,NameNode判断请求是否有效,如文件是否存在,客户端有无权限创建等。 注册块成功后,NameNode返回客户端一个DataNode的列表,该列表中是该块可存放的Locations 客户端通过DFS OutputStream 向列表中第一个DataNode写入块,写入完成时,第一个DataNode向列表中下一个DataNode发送写操作 之后的DataNode重复上面的一个步骤 列表中所有DataNode都接收到数据并且最后一个DataNode校验数据正确性完成后,返回一个确认信息给客户端 客户端继续发送下一个块,重复以上的所有步骤 所有数据发送完成,关闭写入流,写操作完成以上我们感受到写入的过程~同时可以发现数据块存储时候的副本是NameNode发送来的DataNode列表决定的,总的来讲还是很好理解的。 如果你还是没理解这个过程那么配合下面的图片食用更佳!  有了写流程就要来讲讲读流程了! HDFS读流程读流程和写流程实际上是差不多的 Client获得了想要读的Distributed File System 实例后,通过RPC和NameNode通信,获得第一批block的locations,这些locations按照拓扑结构排序,据客户端近的排在前面 Client通过FS Data Input Stream对象调用read方法,从距离客户端最近的DataNode读取数据,如果无法连接,则自动联系下一个DataNode 第一个block块数据读完,关闭指向第一个Block的连接,接着读取下一个block 第一批block都读完之后,去NameNode获取下一批block的locations,继续读,直到所有的这个文件被拆成的block都被读完,就关闭流同样的配合下面的图片食用更佳! 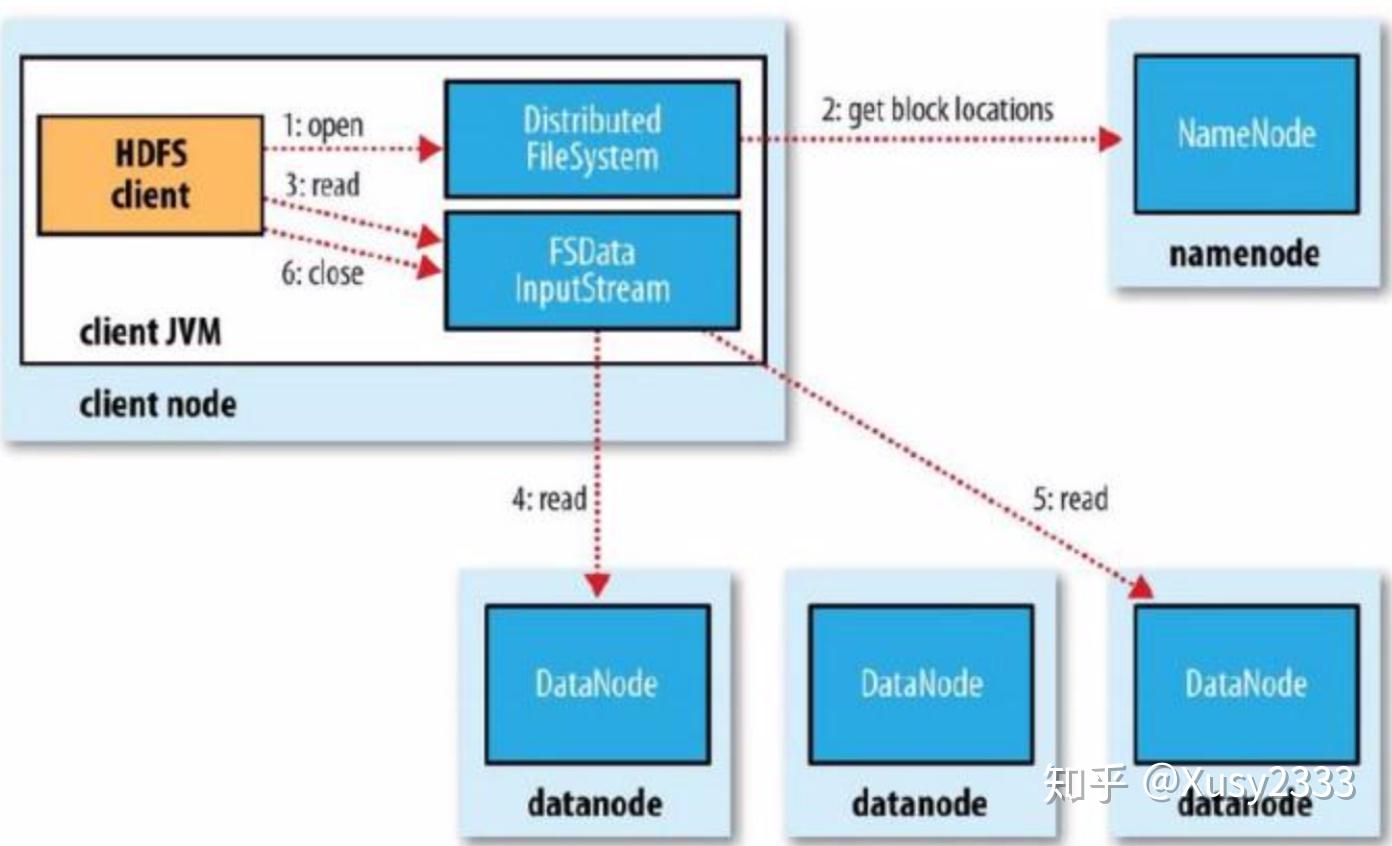 HDFS的机架感知 HDFS的机架感知(这个等我下次再更新吧这次不想写了QAQ) 你还记得上面提到的元数据和一些乱七八糟的名词吗?让我们在本文的最后,你已经了解了这么多Hadoop和HDFS相关基础知识的时候,再来谈谈元数据吧! 再来谈谈元数据的存储、载入和更新NameNode里使用两类非常重要的本地文件保存元数据信息,就是我们上面提到的fsimage镜像文件和edits编辑日志文件。那么到这里的话你再来看看上面关于元数据和NameNode的相关介绍会不会更明白些呢?实际上就是这两个文件完成了元数据的存储。 当NameNode启动时: 通过fsimage读取元数据,载入内存。 接下来执行edits中的记录,在内存中生成最新的元数据。 生成之后清空edits,保存最新的元数据到fsimage 最后收集DataNode汇报的块的位置信息这些东西放到一起,NameNode启动时做的这些操作就正好包含了元数据要存的那些内容呀!你说巧不巧! 当NameNode运行时: 若对文件创建和写操作,则记录到我们的日志文件edits里 接下来更新存在内存中的元数据 最后收集DataNode汇报的块的创建和复制信息以上结合介绍元数据与NameNode部分,大概两个本地文件和元数据就是这么回事啦! 再来谈谈Secondary NameNode知道了Secondary NameNode是啥一般要做啥之后,我不知道你会不会想这个问题:这个东西相当于对NameNode的一个备份,我们已经对NameNode还蛮了解的了,我知道NameNode怎么工作的了,那这个Secondary NameNode到底咋回事啊? 最后让我们来看看Secondary Namenode的运行过程吧 Secondary Namenode根据配置好的策略决定多久做一次合并:fs.checkpoint.period和fs.checkpoint.size 通知NameNode现在需要回滚edits日志,此时Namenode的新操作将写入新的edits文件 Secondary Namenode通过HTTP从Namenode取得fsimage和edits Secondary Namenode将fsimage载入内存,执行所有edits中的操作,新建新的完整的fsimage Secondary Namenode将新的fsimage传回Namenode Namenode替换为新的fsimage并且记录此checkpoint的时间以上 其实本来想这篇文章先简单介绍Hadoop和HDFS,Mapreduce,YARN..但是写完HDFS的简单介绍就不想继续写下去的我Orz那么Mapreduce我们下次有机会再讲吧! 写得迷迷糊糊的如果有什么问题欢迎联系我~ 既然这篇001只是一个简单介绍..那么我就不讲太多啦!想看剩下的HDFS更详细的介绍可以到官网 去看看呢!这篇博只是想让我们后续的学习能更加顺利知道这是在讲什么想干嘛的一个东西.. 我们下次再见!欢迎有问题在下方评论区/ wx: xsy9915/ mail:[email protected] 联系我! 本站后续也将更新Hadoop, Spark等相关内容,欢迎持续关注~最后我发现写好的markdown导入知乎真的太丑了!!!原文首发在我的网站里原文没这么丑的QAQ知乎这个排版怎么这么不好看啊QAQ大家凑合看吧..抱拳! |
【本文地址】
今日新闻 |
点击排行 |
|
推荐新闻 |
图片新闻 |
|
专题文章 |